Varias cosas han pasado desde que empezamos a probar en nuevo modelo de Builds en VSTS, primero creamos una build sencilla que desplegaba a una Azure Web App, luego probamos como usar los Resource Groups para desplegar entornos, luego retiramos el paso de despliegue de la Build para trasladarlo a Release Management luego de su integración con VSTS, y hace poco agregamos Sonar como parte del proceso de análisis de nuestro código dentro de la compilación.
Y como el ciclo de evolución del proceso DevOps nunca para, en esta ocasión veremos como hacer algo a lo que le he tenido bastante respeto desde la época de las builds con el modelo XAML, en este caso la evaluación de la performance y estabilidad de nuestras aplicaciones web desplegadas.
En corto, la posibilidad de probar nuestras aplicaciones Web precede aun a .Net, recuerdo cuando probé Web Application Stress Tool (Homer) para hacer unas pruebas sencillas sobre ASP Clásico, de ahí le perdí el rastro pero la cosa se puso interesante desde Visual Studio 2013 se permite que los tests de carga se basen en las capacidades de la nube, lo cual significa que durante nuestras pruebas se provisionaran las maquinas virtuales que hagan falta para cubrir la cantidad usuarios y peticiones deseadas, esto ya lo había probado desde Visual Studio (revisar aquí y aquí), con buen resultado, pero… ¿como hacer que estas pruebas se ejecuten cuando se produzca cierto tipo de despliegue?
Antes de proseguir hay algunas consideraciones a tener en cuenta:
Los recursos que Azure provisiona para efectuar estas pruebas tienen un costo (si se va por encima de los minutos de carga incluidos con nuestra suscripción de VSTS) por lo que hay que tener cuidado de no lanzar estas pruebas por cada commit que los desarrolladores efectúen, así que la sugerencia general seria tener un sitio de DEV donde se despliegue continuamente pero sin efectuar las pruebas de cargar, luego definiríamos un sitio QA (por ejemplo) al cual se desplegara ya sea de manera manual o de manera programada el contenido existente en DEV (con Release Management lo que se despliega son paquetes que no necesariamente son recién compilados) y al efectuar ese despliegue se lanzaran las pruebas de carga, las cuales si son exitosas indicar que en el proceso de despliegue esta listo para ser sometido a aprobación (si lo hemos definido así) para decidir su pase a otro entorno.
Con estas consideraciones en mente procederemos con nuestra primera prueba para lo cual no sera necesario usar Visual Studio simplemente agregar un paso adicional a nuestro proceso de despliegue, esto es porque a veces lo que nos interesa es simplemente ver que tan bien resiste una URL en concreto a cierta petición.
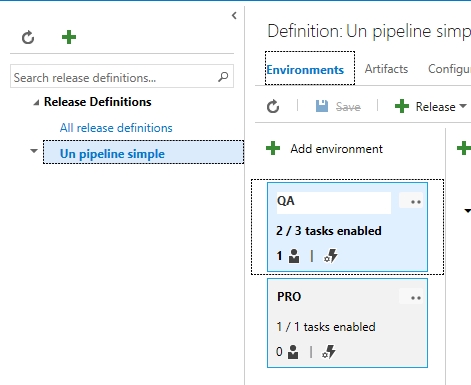
Para esto vamos a la pestaña de Release de nuestra instalación de VSTS, elegimos nuestro plan actual, seleccionamos el «entorno lógico» sobre el cual agregaremos nuestra prueba de carga y agregamos el Step de Cloud-based Web Performance Test, así:
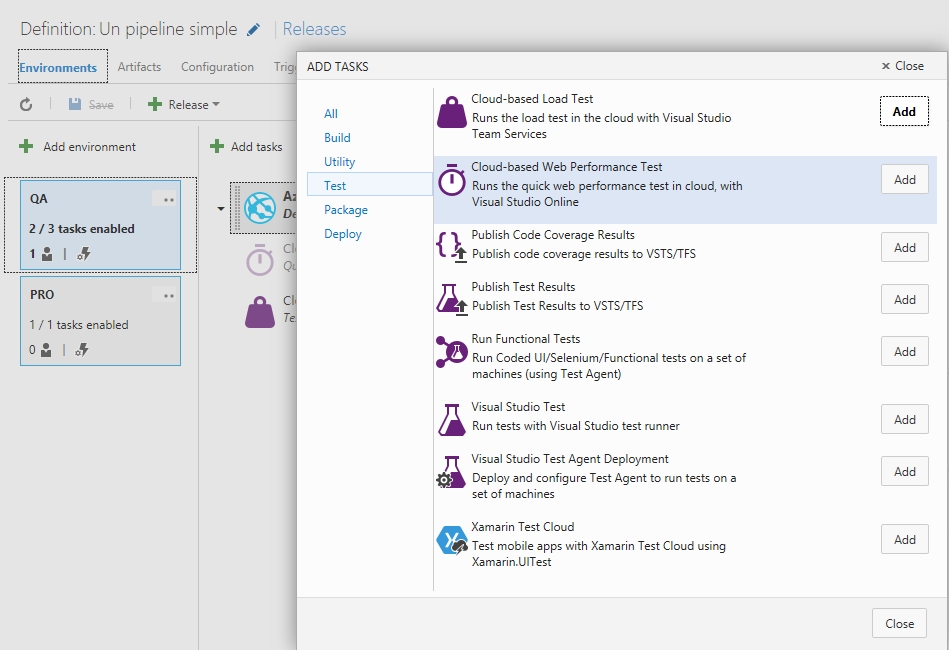
Ok, ahora toca parametrizar el paso para lo cual dejaremos los parámetros mas o menos así, en breve explicare el significado de cada parámetro:
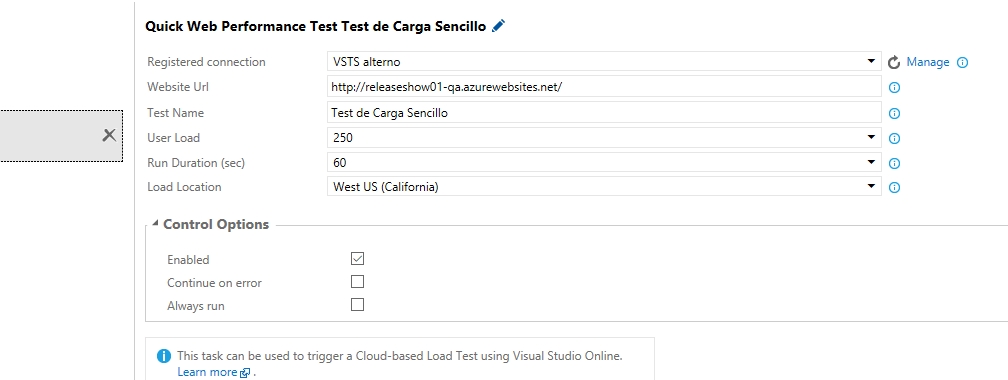
Antes de proseguir prestemos atención al parámetro Registered connection, lo que ocurre es que cada prueba de carga se hace con cargo a los recursos y facturación de una cuenta de VSTS y podría darse el caso de que la organización tenga mas de una instancia de VSTS, así que corresponde indicar explícitamente dicha cuenta, así que hagamos clic sobre el enlace que dice Manage, que nos abrirá una nueva pestaña en el navegador para agregar un Endpoint (como ya hicimos anteriormente para enlazar Sonar y la cuenta de Azure), y en este caso elegiremos Generic, así:
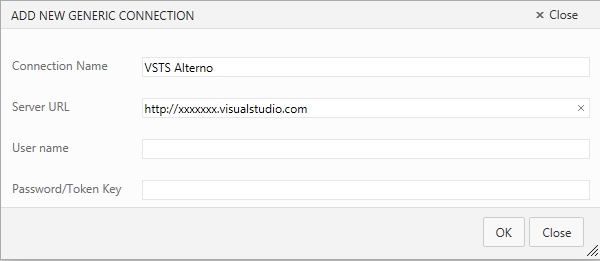
 Y llenamos los parametros de configuración de nuestra instancia de VSTS, pero ojo, al hacerlo deberemos utilizar los datos de nuestra conexión alterna a VSTS, algo de lo que hablamos hace tiempo cuando empezamos a trastear con Git.
Y llenamos los parametros de configuración de nuestra instancia de VSTS, pero ojo, al hacerlo deberemos utilizar los datos de nuestra conexión alterna a VSTS, algo de lo que hablamos hace tiempo cuando empezamos a trastear con Git.
Listo, ya hemos enlazado nuestra prueba de carga a nuestra cuenta de VSTS, personalmente yo agregaria un checkbox que permita usar la instancia actual y no hacer nada mas, pero siempre es bueno tener una conexión alterna a VSTS especialmente de cara a la integración con herramientas de terceros en Git.
Ok, antes de grabar repasemos los parámetros que estamos configurando:
- Registered connection: como lo vimos, la instancia de VSTS sobre la cual se hara la facturación de esta prueba de carga.
- Website Url: La dirección que vamos a probar, en este caso estoy probando la raiz del site (o mejor dicho del slot) en que acabo de hacer el despliegue, cabe indicar que tranquilamente podria haber colocado cualquier URL interna de nuestro site, o peor aun, una URL totalmente externa no manejada por nosotros, pero eso no queremos ¿verdad?
- Test Name: El nombre con el que identificaremos a esta prueba.
- User Load: La cantidad de usuarios supuestos que se estarán conectando a nuestra URL.
- Run Duration (sec): El tiempo de duración de la prueba.
- Load Location: La zona geográfica de Azure desde donde se hará la prueba, es muy interesante y conveniente hacer la prueba desde una zona que no sea la que aloja a nuestro site, en mi caso la URL esta alojada en East-2, así que la prueba la estoy lanzando desde West.
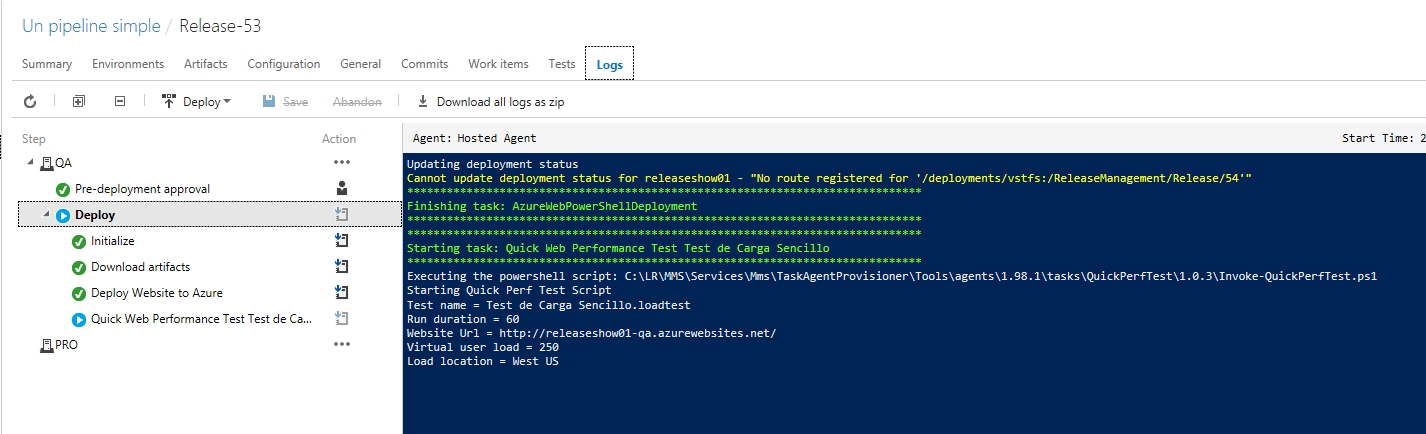
Marcamos Enabled y grabamos, ya estamos listos para empezar, asi que lo mas sencillo sera hacer un cambio en nuestro codigo fuente, lanzar una nueva Build manualmente, o si queremos divertirnos relanzar un paquete antiguo al ciclo de Release, en todo caso esperamos un poco y veamos cuando nuestra Release se empieza a ejecutar y llega al paso que hemos agregado:
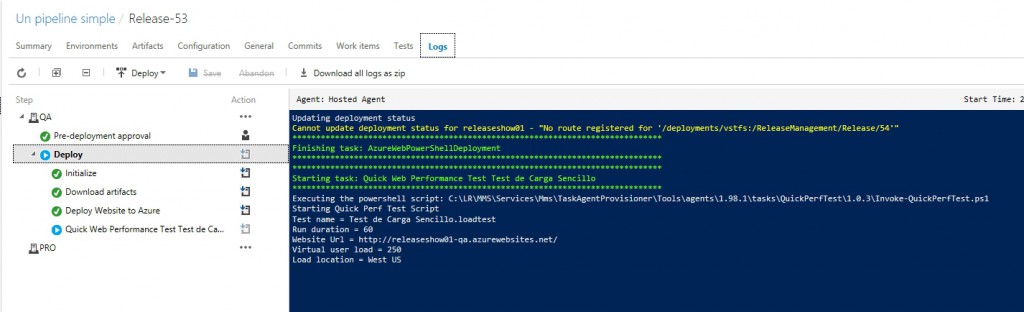
Para después terminar:
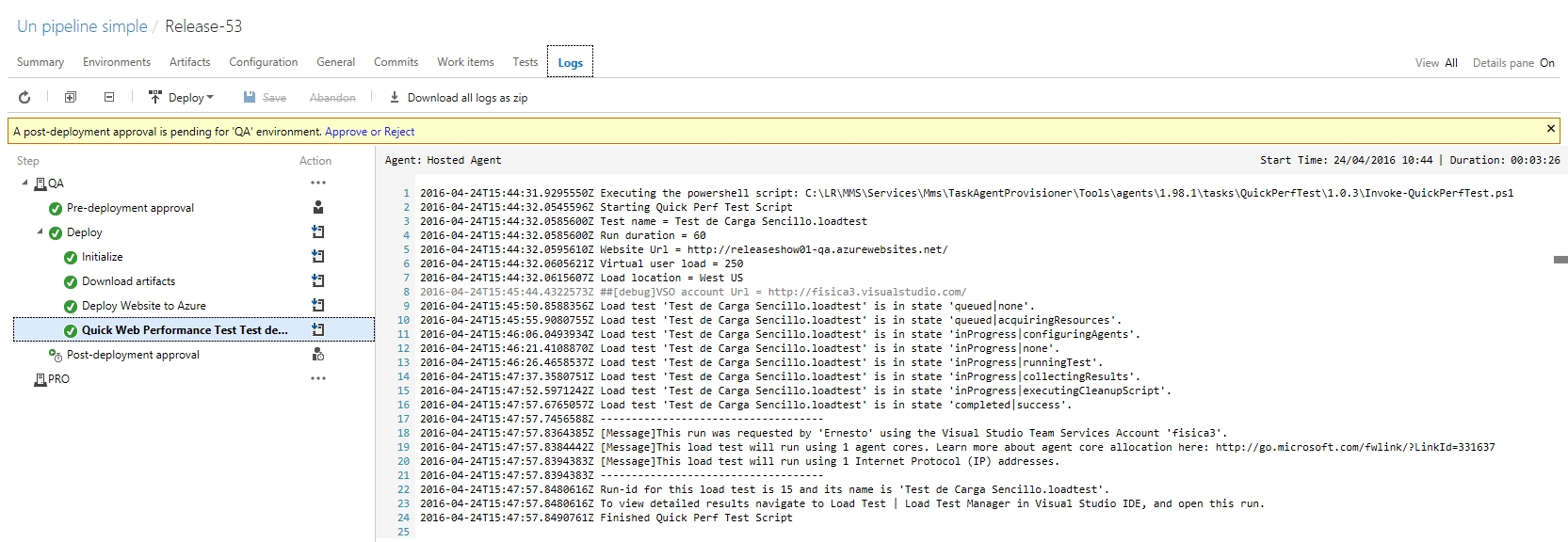
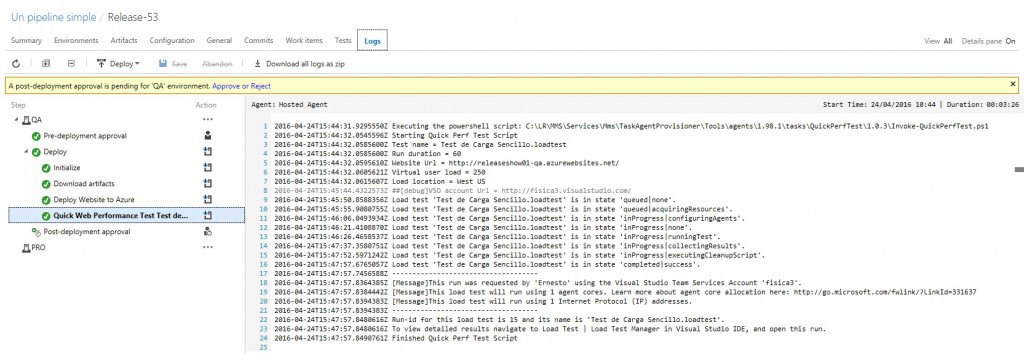 Normalmente pasaríamos a aprobar o rechazar esta Release, pero ahora me interesa conocer los resultados de nuestra prueba, así que vamos a la pestaña Tests, y elegimos la opción LoadTest, para luego seleccionar la prueba mas reciente (en mi caso tengo algunas pruebas anteriores, pero si es la primera vez deberías tener una sola prueba en tu lista).
Normalmente pasaríamos a aprobar o rechazar esta Release, pero ahora me interesa conocer los resultados de nuestra prueba, así que vamos a la pestaña Tests, y elegimos la opción LoadTest, para luego seleccionar la prueba mas reciente (en mi caso tengo algunas pruebas anteriores, pero si es la primera vez deberías tener una sola prueba en tu lista).
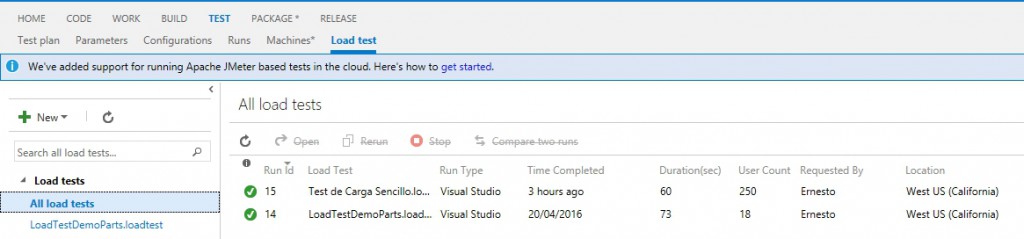
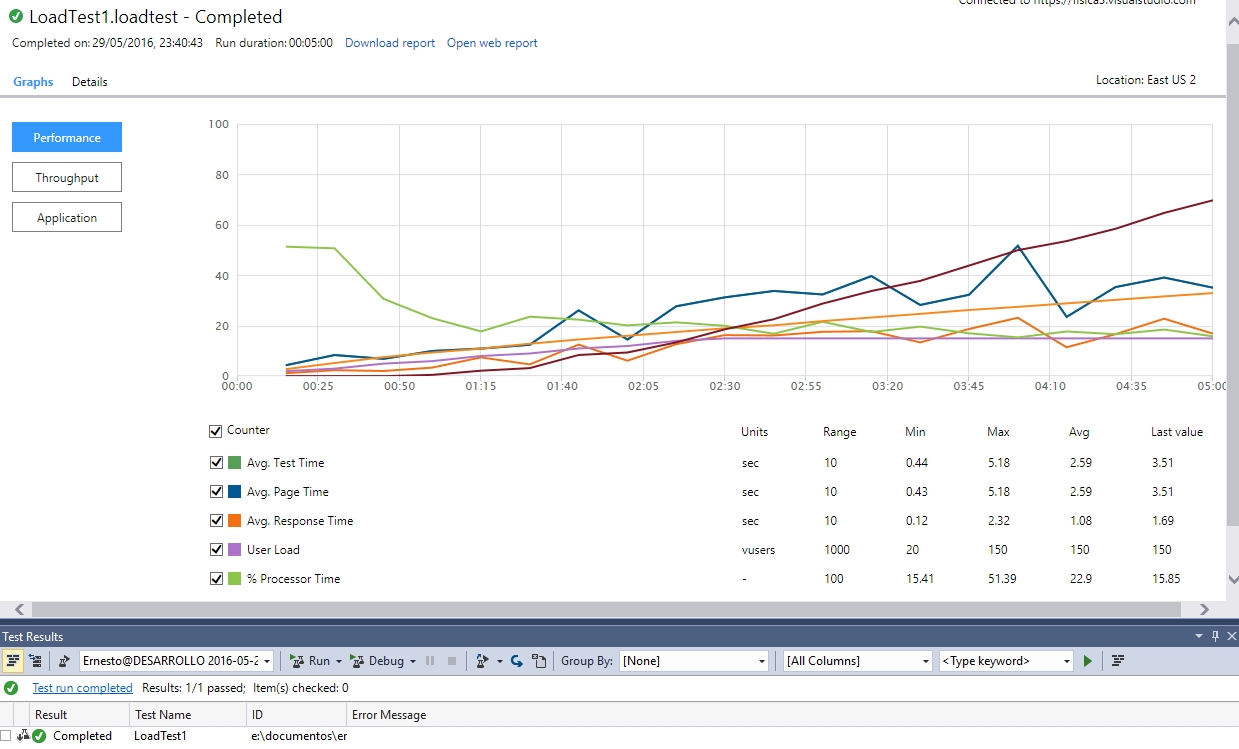
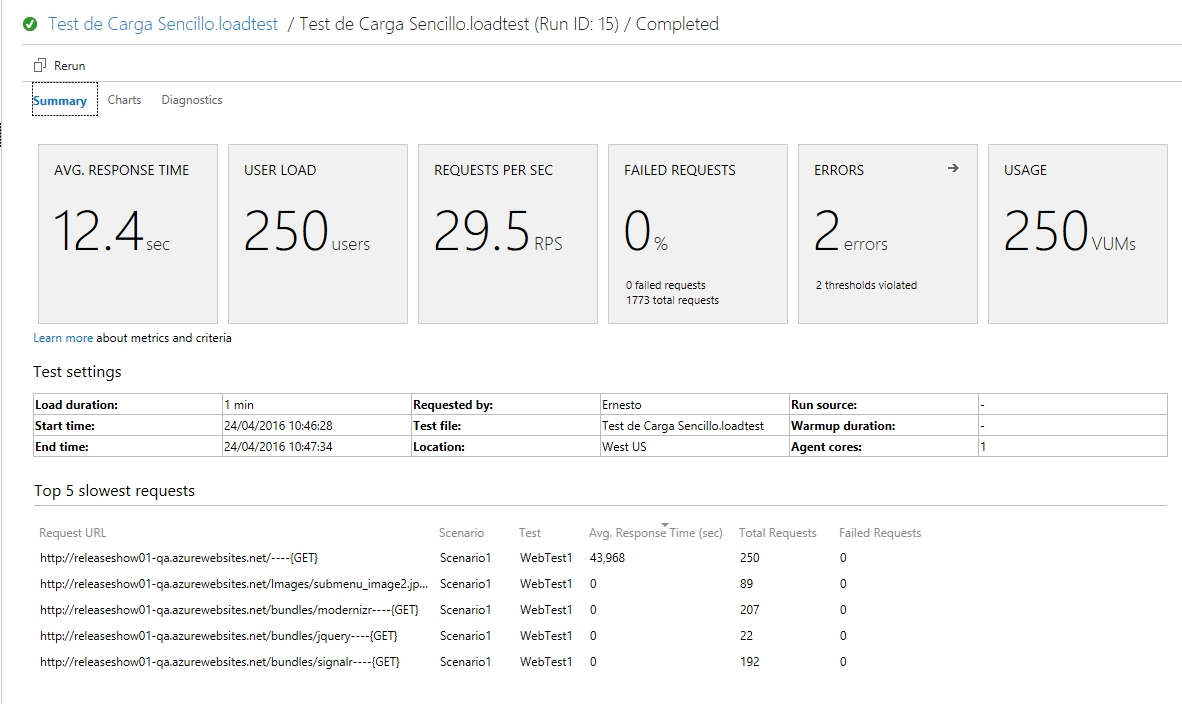
Y así entramos a un detalle de los resultados de la prueba:
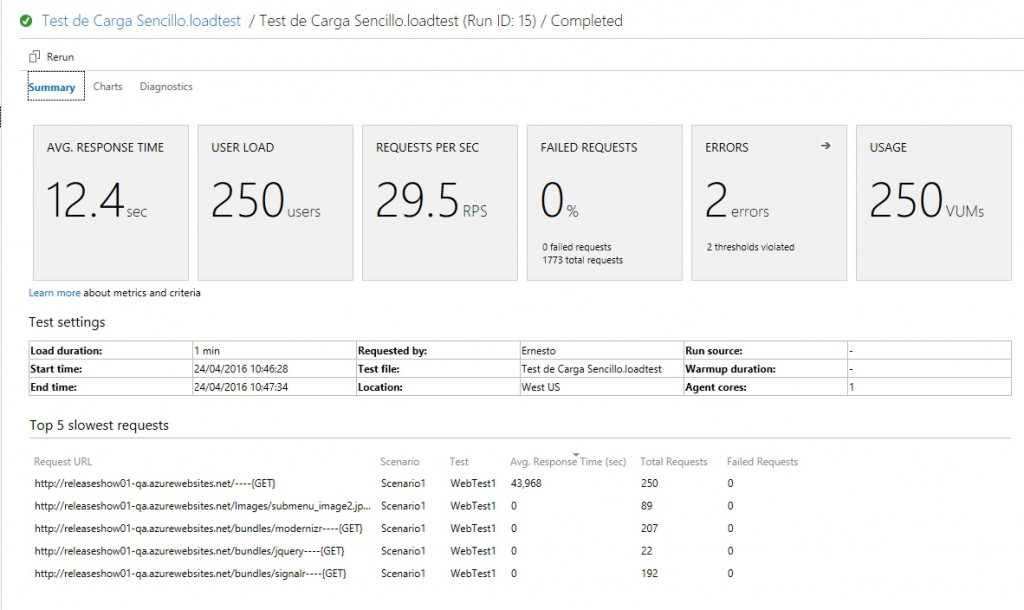
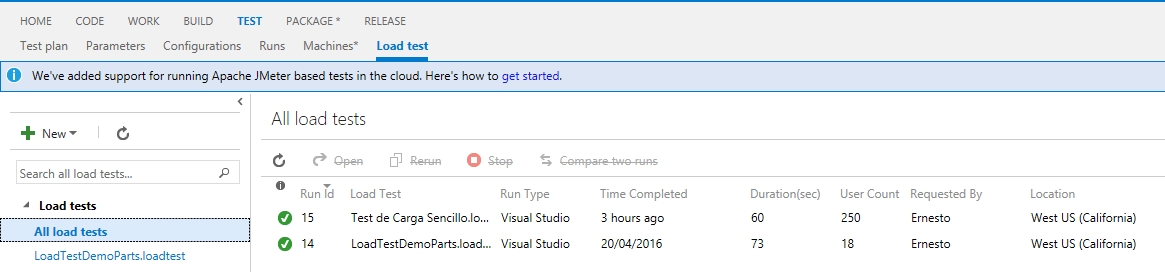
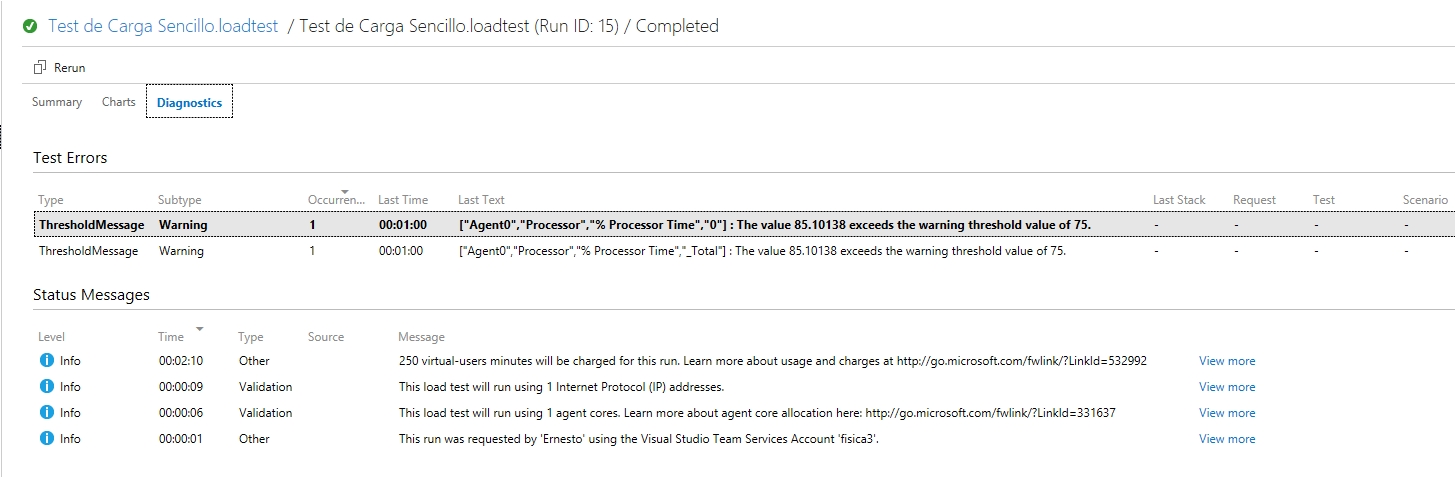
Notemos algo interesante, aparentemente nuestra prueba salio ok (o sea, no hubo errores 500 o timeouts) pero el panel nos indica 2 errores, así que veamos el detalle:
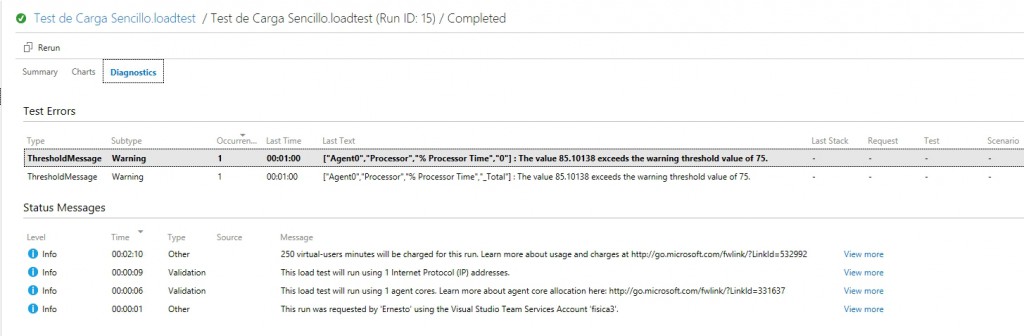
En mi caso el mensaje de error dice «The value 85.10138 exceeds the warning threshold value of 75«, lo cual nos viene a indicar no un error en el sitio que estamos probando sino un exceso en la capacidad de la instancia provisionada para hacer la prueba, esto apunta a que forzamos la maquina dandole 250 usuarios concurrentes, lo cual se relaciona a las pocas opciones de configuración que ofrece este tipo de prueba.
Listo, sencillo y ya podemos empezar a sacar conclusiones, pero como verán esta prueba es muy sencilla y en adición al ya mencionado problema del threshold no permite saber si por ejemplo el comportamiento es diferente desde un browser u otro, desde un tipo de red, etc, para lograr este tipo de análisis lo que se nos ofrece es la posibilidad de crear un test muy detallado desde dentro de Visual Studio y que cuando se efectúe el despliegue Visual Studio Team Services pueda «leer» todos estos parámetros archivados y ejecutar tras bastidores las pruebas programadas, esto sera tema de nuestro próximo post, de momento sugiero familiarizarse con este tipo de prueba, pues los conceptos siguen siendo validos cuando los escalemos, aparte de que estas pruebas tienen su lugar si hacemos peticiones Get que luego repercuten a nuestra BD, o queremos probar la mejora si usamos un servicio de cache, etc.
Espero sus comentarios 😉