

Y uno al leer el título podría pensar que se esta incurriendo en un desprecio hacia el cliente que nos ha encargado el desarrollo de un software, pero nada más lejos de la realidad, la reflexión viene a algo que aun sigue siendo mal entendido por quienes estamos involucrados en el desarrollo de software.
No cuento nada nuevo que tradicionalmente (modelo “cascada”) el desarrollo de software tiene un historial de fracasos totales o parciales, ya sea en funcionalidad incompleta, sobrecostos de tiempo y dinero, lo cual lleva como consecuencia en que los aun medianamente exitosos tengan la presión por conseguir entregar “lo que se pide” “a tiempo”, y claro muchas veces sin importar el “cómo” que es a lo que nos lleva el título de este post, el cómo la obsesión por entregar algo que el cliente pueda usar hace que se pierda la perspectiva global del problema.
Y el problema (deuda técnica) ya es conocido: métodos de más de 400 líneas de código, código muerto y/o duplicado, lo cual deriva en poca mantenibilidad, bugs como consecuencia de la extensión de la funcionalidad, pobre performance, etc; síntomas que hacen que el que hereda un código desee ir corriendo tras el que hizo el código originalmente, (y un cliente pagando resignado los costos de implementar un parche o una mejora menor).
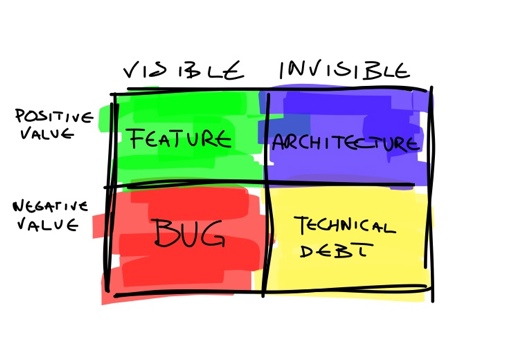
En este punto se nos podría decir que esto ocurre porque el equipo de desarrollo no aplicó un buen patrón de diseño, que no siguió los principios S.O.L.I.D., lo cual si bien tiene algo de cierto no es sino la segunda capa de un problema mayor que veremos en breve.
Se pensaría que con la irrupción de las metodologías ágiles la situación ha estado cambiando, pero no, la realidad no es tan hermosa, pues si bien ahora tenemos más visibilidad sobre los elementos (historias de usuario) que se están desarrollando no debemos de olvidar que las metodologías imponen un proceso de priorización, en el cual lamentablemente las historias funcionales (si, las que “dan valor”) toman precedencia siempre sobre las técnicas, las cuales tienen que rogar para hacerse un lugar en el sprint o en el flujo del Kanban, y muchas veces nunca logran entrar por la sencilla razón de que “no hay como justificar ante el cliente algo que no se ve que le reporte valor”. Así pues, se cumple con la entrega de funcionalidad continuamente, pero seguimos acumulando deuda técnica pues, a pesar de seguir perfectamente el proceso, sólo nos estamos enfocando en entregar un software que funcione sin fijarnos en qué es lo que hay detrás de este software que se entregó perfectamente en plazos pues lo importante es que funcione, ¿no? ¿qué hay deuda técnica? tranquilos, eso lo solucionamos con una refactorización circunstancial (léase: arreglamos cuando podamos y no nos quite mucho tiempo).
Recomiendo leer este interesante articulo de Lucas Ontivero donde nos cuenta como las cosas han seguido yendo mal en el lado técnico a pesar del agilísimo.
Adicionalmente tenemos el factor del QA (Quality Assurance), uno podría creer que en empresas grandes este equipo tendría una visión integral de la calidad del producto, lo cual debería incluir tanto la verificación de la mantenibilidad y calidad del código como de la validación de la arquitectura, pero no, al parecer su visión va sólo al lado funcional, o sea a lo “visible” del gráfico anterior, siendo que temas como la mantenibilidad “lo ve el equipo de desarrollo”, así pues por un lado se exige un cumplimiento funcional (muchas veces sin entender las razones por las que “la gente de desarrollo” opto por implementar de una manera diferente a como QA lo pensaba) estricto pero por otro lado se omite la validación de la calidad de lo técnico, pues claro… no es lo que ve el cliente de manera directa, por más que este sea el que luego tenga que pagar los “intereses” de la deuda técnica(*). No se ustedes pero si un equipo que se supone se encarga de la “calidad” durante el ciclo de desarrollo ignora la parte técnica de la implementación (¿alguien dijo auditorías?) , le esta haciendo un flaco favor al proyecto y al cliente.
Así pues mucho del problema viene dado por la importancia que se le quiere dar al elemento técnico del proyecto, el cual viene tradicionalmente es relegado por debajo del administrativo, siendo que muchos profesionales hacen gala de haber tocado muy poco los elementos correspondientes a la programación en su formación profesional, lo cual en mi opinión generalmente (he conocido excepciones) ocasiona que no se sepa (debido a que a veces no se entiende) el impacto de una decisión técnica que se tome en cualquier etapa del desarrollo, razón por la cual prime el componente funcional/visible a la hora de definir prioridades en el desarrollo.
Afortunadamente hay caminos de solución, uno de ellos es tratar de entender qué es lo que ha derivado en la creación del Manifesto for Software Craftsmanship como una evolución del Manifiesto Agile (esto lo explica muy bien Edson en esta presentación); y por otro lado, dentro del marco de las metodologías ágiles, reconocer de manera visible el rol que deben de jugar los componentes técnicos, en ese sentido me sorprendió muy gratamente como en su reciente conferencia «Lean from the Trenches» Henrik Kniberg indicó claramente cómo dentro de su proceso ágil (basado en Kanban) había reservado, dentro de su tablero, el espacio necesario para las historias técnicas, de esta manera

Es que como Henrik dijo, en un mundo ideal sólo habría historias de negocio, pero no estamos en un mundo ideal, los problemas técnicos existen y no podemos pretender seguir ignorándolos, o creer ingenuamente que efectivamente lo “solucionaremos después”, o ya en el lado extremo seguir en la ilusión de que cualquier programador podrá implementar algo si le damos una especificación funcional completa y detallada.
Entonces, regresando al título de este post, creo que debe de quedar claro que no es que no tengamos como meta el entregar funcionalidad y software, sino también validar el cómo llegamos a ese entregable, procurando (entre otras cosas):
- Dar el espacio a las historias técnicas cuando corresponda, y no relegándolas a cuando “haya tiempo”.
- Sospechar del programador que defiende una mala implementación con un “pero funciona”.
- Ser consciente de los riesgos que significa ir por el camino rápido en aras de entregar la funcionalidad pedida.
- Que todo el equipo (y no sólo el que implementa) sea consciente de lo que hay en la implementación (arquitectura, algoritmos, etc) y de como eso condiciona los tiempos de desarrollo, especialmente cuando se trata de agregar una nueva funcionalidad.
- Valorar el factor técnico, procurar la mejora de las habilidades técnicas de los desarrolladores: mentorship, revisión por pares, dojos, etc.
Claro que mucho de esto tendría que ir de la mano con un reconocimiento dentro de las organizaciones al rol que juegan las TI en su crecimiento como negocio, pero por ese lado la cosa esta bien complicada.
(*) Se entiende como “intereses” de la deuda técnica al hecho de que conforme pasa el tiempo será más difícil corregir las malas decisiones o malas implementaciones de código, ya sea porque el desarrollador que implementó algo de manera críptica ya no se encuentra en el equipo, porque nueva funcionalidad superpuesta generó más dependencias o simplemente porque por el tiempo que pasó ya es más difícil acordarse el porque se tomó esa decisión que “parecía buena en su momento”.
