El reciente anuncio de AWS , sobre el lanzamiento y futura disponibilidad de Aurora Serverless V2 , me ha hecho regresar a unas reflexiones, acerca de cómo la nube nos obliga a enfocar las compras de otra forma, pues de otra manera no sacaremos ventaja real de las innovaciones que trae esta tecnología, que (se supone) queremos introducir como parte de nuestra estrategia tecnológica y (sobre todo) de negocios.
Empecemos con la contextualización, en una forma simpática:
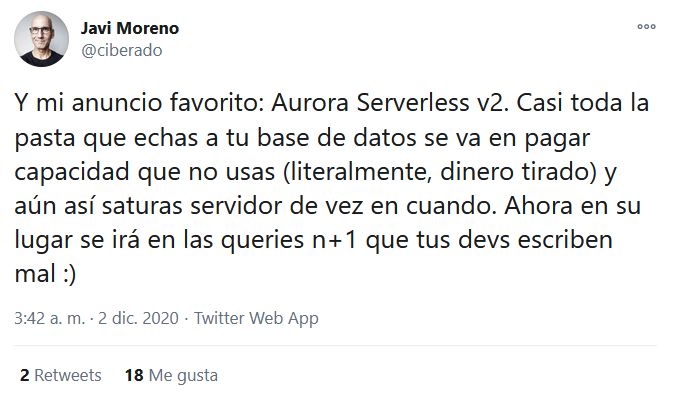
En este tweet Javi nos recuerda, de manera sencilla, los esquemas de trabajo usuales en Bases de Datos (y extrapolables a casi servicio de cómputo): para evitar quedarnos cortos de capacidad de proceso las organizaciones estiman “hacia arriba” la capacidad que necesitarán (usualmente servidores y número de cores) para cierto requerimiento, con lo cual damos “tranquilidad” a la organización si dicha aplicación es de misión crítica (al precio de tener capacidad sin usar durante buenos tramos de la operación); vamos, lo usual en el mundo on-premise y tiene cierto sentido porque el agregar, retirar, o cambiar de uso a un conjunto de servidores no es cosa sencilla. Claro, me dirán que la virtualización y tal, pero nos olvidamos que aún en un esquema virtualizado trabajamos con un “colchón” grande para ir asignando sucesivamente la capacidad demandada, por lo que para este análisis prescindiremos del modelo de virtualización gestionado por la organización.
El caso es que el anuncio de AWS pone el foco en dos factores claves de lo que ha sido la “propuesta cloud”: escalabilidad y pago por uso. Sí pues… lo que hemos venido escuchando en los últimos 10 años “arranca con un servidor y escala automáticamente según la demanda y sólo paga a fin de mes por lo realmente consumido”; sí, el argumento no es nuevo y no deja de ser cierto, la diferencia es que usualmente este argumento ha sido orientado a las aplicaciones (generalmente web), no a las BD.
En ese sentido, esto continua la senda de los últimos dos o tres años: más ofertas de bases de datos serverless como SQL Database, la v1 de Aurora Serverless, y hace poco Cosmos DB. Estos movimientos de la industria deben indicarnos por dónde van las tendencias; que el viejo modelo de mirar sólo el número de servidores, nodos o cores a desplegar debe cambiar ya; que además de considerar PaaS y Serverless para el desarrollo de aplicaciones (como ya hemos hablado antes), no podemos ignorar ese rumbo de la industria.
A todo esto, si quieres entender un poco mas sobre el modelo serverless (y en este post hablaremos mucho de el), hace poco escribí la serie de artículos Serverless: Realidad y perspectivas (1), (2) y (3) que seguro te servirá.
Finish Reading: Tu estrategia cloud pasa por (re)aprender a comprar