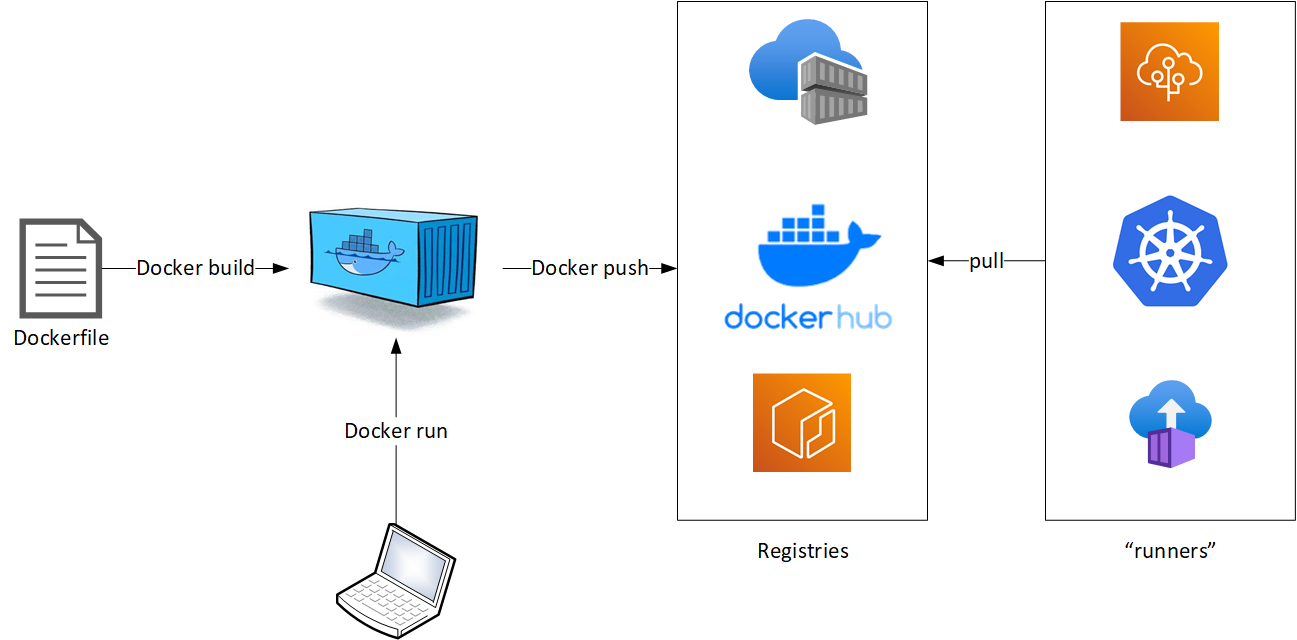
El articulo anterior dejo las bases respecto a como ha ido la evolución de las tecnologías de contenedores, y el contexto en que se ubican los Azure Container Apps (ACA), pero creo que falta precisar un poco respecto a los casos de uso en que se puede aplicar esta tecnología o sus “hermanos” en Azure.
 Empezare con algo que puede que ahora luzca menos glamoroso, pero que si que causo impacto en el momento de su lanzamiento: los Azure Container Instances, como mencionamos en su momento, esta tecnología surge para evitar el tener que lanzar los contenedores dentro de un cluster o de una MV, en ese sentido, que se puede hacer ahora con ellos:
Empezare con algo que puede que ahora luzca menos glamoroso, pero que si que causo impacto en el momento de su lanzamiento: los Azure Container Instances, como mencionamos en su momento, esta tecnología surge para evitar el tener que lanzar los contenedores dentro de un cluster o de una MV, en ese sentido, que se puede hacer ahora con ellos:
- Lanzar servicios de “servidor” basados en contenedores, que no requieran una orquestación ni escalamiento, como puede ser un servidor SFTP en la nube
- Experimentación individual, en desarrollo, de un contenedor que luego se integrara como parte de una plataforma de microservicios.
- ML, si, esto es algo que aprendí mientras preparaba mi certificación en Azure AI, resulta que algunos modelos sencillos de ML se pueden desplegar en Azure Container Instances, interesante la verdad.
- Dar soporte a un escalamiento sencillo a los clusters AKS, creando virtual nodes en escenarios en que no es conveniente escalar el cluster hacia nodos “reales”, ojo este modelo tiene algunas limitaciones por lo que toca revisar si es la solución para nuestra necesidad en concreto.
Como se puede ver, los ACI aun dan mucho juego, pero de nuevo vamos a la pregunta respecto a los casos de uso que corresponden a AKS y ACA, y esto ya entra en los terrenos del mal llamado “juicio de experto” que son tan subjetivos, pero trataremos de delimitar la cancha: Finish Reading: ¿Cuales son las diferencias entre Azure Container Instances, Azure Container Apps y Azure Kubernetes Services? (y ii)