

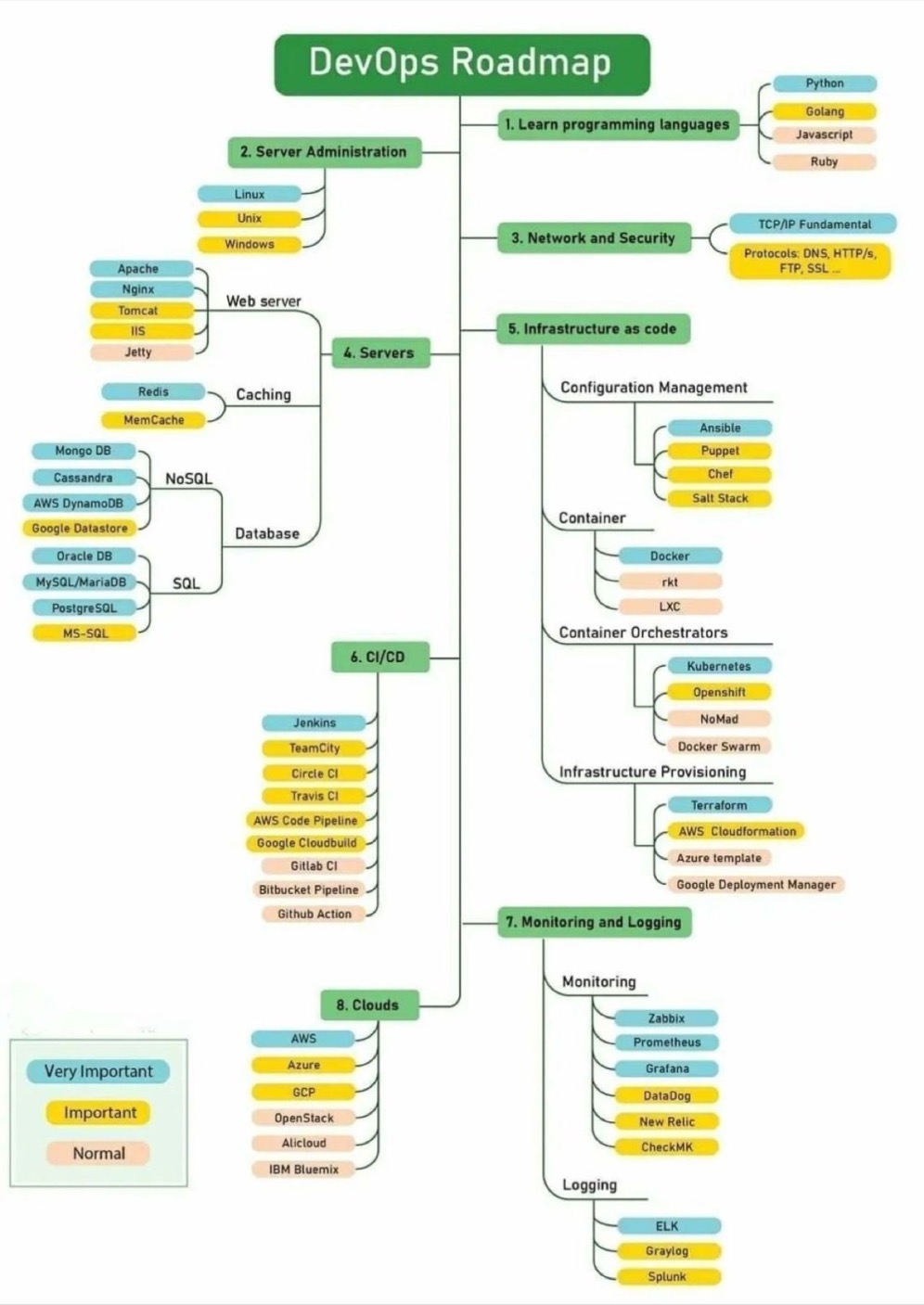
Estas conversaciones siempre terminan aflorando, pero casi siempre coinciden por la misma temporada, y en esta ocasión lo que me llevo a escribir esta nota fue la siguiente imagen que me paso mi enamorada:
La vi y dije «Upss ¿aun siguen con eso?», y es que si no es raro encontrar estas «guias» o recomendaciones para el que quiera iniciar su «carrera como DevOps», lo cual ya de por si esta mal porque recordemos que DevOps es una practica/filosofía/enfoque y no un rol, pero esta vez no ahondaremos en ello, sino nos centraremos en el entendimiento de DevOps y de lo que queremos lograr con su adopción.
Empecemos viendo el gráfico, y listemos las categorías:
- Lenguajes de Programación
- Administración de Servidores
- Redes y Seguridad
- Infraestructura como Código
- CI/CD
- Logs y Monitoreo
- Nube
Si, lo mas obvio es que (como de costumbre) la lista es de herramientas, y nada de practicas, pero es que aun tratándose de herramientas, faltan categorías relevantes, por ejemplo… donde ¿están Selenium, Cypress, PlayWright y otros? (Testing) ¿Se ha considerado la relevancia de herramientas como LaunchDarkly, Optimizely o App Configuration? (feature flags).
Con esto entendemos el problema en su verdadera magnitud, no solo es que al hablar de DevOps se piense solo en Automatización y Herramientas, sino que el dialogo DevOps ha sido monopolizado por un enfoque IT Pro, en el cual las practicas quedan acotadas a el funcionamiento de la infra (importantisimo, ojo, no se malentienda), donde es mas fácil conseguir hablar de estrategias de ruteo en redes que de experiencias en Feature Flags o el impacto del branching en tu estrategia.
En parte ha tenido culpa el mercado y los reclutadores que básicamente han considerado a DevOps como la «modernización del sysadmin», obviando que esa modernización existe y tiene otro nombre: SRE (Site Reliability Engineering), enfoque que efectivamente tiene áreas de solapamiento con DevOps, y que es complementario para la buena marcha de la tecnología en la organización.
Luego de esta enésima precisión ya podemos plantearnos algunas bases de como introducirnos en la practica DevOps, al menos según mi experiencia (*) :
- Venir de alguna de las canteras: desarrollo, QA o gestión de infra (IT Pro/sysadmin), personalmente no creo conveniente que un egresado se plantee ir directamente a este rubro sin antes haber tenido conocimiento en la cancha de alguna de las áreas involucradas.
- Si se es desarrollador «ser consciente» de el donde corren o van a correr las apps que se desarrollan (olvidar el «en mi máquina funciona»), y si se es de infra entender las diferencias de expectativas funcionales y no funcionales de las de las aplicaciones que toca gobernar.
- Curiosidad por la experimentación, prueba y error, pues esto es algo que nos pasara en el día a día probar y validar antes de que la automatización este completa.
- Desarrollar una capacidad de adaptación y autoaprendizaje, no es necesario saber todos los bloques, pero si las bases para poder movernos entre múltiples contextos de manera simultanea, sin llegar a ser experto en todo.
- Comunicación, capaz de adaptarse a distintos diálogos técnicos, pues un día estaremos hablando de los problemas de diseño de la aplicación y como esto impacta en el despliegue, y al otro conversando sobre la configuración del ambiente de Producción.
¿Y sobre el stack tecnólogico? me dirán, pues si, es importante, pero siendo que cada organización es muy particular respecto a lo que usan, trataremos de acotarlo a lo fundamental (recordemos, estos son consejos para principiante), ya que lo particular uno tendrá que profundizarlo según la necesidad («Capacidad de adaptación»… recuerden), y esto es muy importante pues en uno de mis pasos intermedios en este mundo me toco ir con «otra nube» y «otra herramienta CI/CD» y caballero toco aprender y esa experiencia fue valiosisima:
- Git y estrategias de branching con énfasis en Trunk Based Development.
- Herramientas CI/CD: Azure DevOps, Gitlab, Codefresh, etc.
- Networking: TCP/IP, DNS, diseño básico de redes, no saben la cantidad de veces que la topología de red tendrá un gran impacto sobre tus pipelines de despliegue.
- Fundamentos de Testing y TDD (que no son lo mismo).
- Fundamentos de Cloud e Infraestructura como código (la nube llego para quedarse y toca aprender).
- Gestión básica de Sistemas Operativos: Windows y Linux.
- Y claro, experiencia programando lo cual incluye a quienes vienen de las canteras QA.
Ok, bueno ya todo va tomando forma, pero, nos olvidamos de lo mas importante: el propósito, que es lo que esperamos conseguir con DevOps, ya que sin tener claros los objetivos todo lo arriba mencionado no sirve de nada, y esto es de veras vital en todo esfuerzo DevOps ya que hace un tiempo se me dijo «El objetivo de hacer DevOps es tener entornos homologados«, lo cual indicaba a todas luces una visión parcial y errónea de lo que realmente se espera con DevOps: mejorar (acelerar) la entrega continua de valor a los usuarios de nuestra organización, para de esta forma lograr que la organización este mas preparada para reaccionar ante los cambios del entorno lo cual, en el caso de empresas, termina beneficiando positivamente la cuenta de resultados (**).
Entendiendo esto, ya las piezas encajan, nuestros conocimientos deben orientarse a ello, buscando la tan difícil sinergia entre áreas en pro de lograr los cambios, pero queda una pregunta ¿como nos damos cuenta de que estamos haciéndolo bien?
Es que si, cuando se trata de un cambio que involucra tanto lo cultural como lo tecnológico es difícil validar si lo aplicado va teniendo resultado, los numeros son importantes, y en este caso las Métricas Dora nos dicen por donde mirar:
- Deployment Frequency: con qué frecuencia una organización despliega correctamente a producción
- Lead Time for Changes: la cantidad de tiempo que tarda un commit en pasar a producción
- Change Failure Rate: porcentaje de implementaciones que causan un error en producción
- Time to Restore Service: cuánto tiempo tarda una organización en recuperarse de un error en producción
- Reliability: Latencia, performance y escalabilidad (***)
Pero, y ¿por qué esos indicadores en particular? No hay mucha vuelta que darle, desde la publicación del libro Accelerate se cuenta con evidencia empirica de que unos buenos valores en dichas metricas (y otros criterios como la cultura organizacional Westrum) estan altamente correlacionados a una buena performance de la organización, por lo que con esto sabemos que estamos mejorando si vemos que (por ejemplo) la frecuencia de despliegue ha pasado de mensual a semanal y con menos caidas; datos mucho mas relevantes a la larga que la medición del tiempo de un pase o de horas hombre ahorradas, valores que mejoraran por si mismos si colocamos el foco en los cambios que pide DevOps y medimos donde hay que medir.
Así que para cerrar, diria que tambien un buen punto de partida para el aprendiz seria la lectura de Accelerate y The Phoenix Project.
Gracias por llegar hasta aquí, espero tus opiniones y Feliz 2023!!
(*) Un enfoque similar lo da Carlos Peix en este comentario que nunca pierde vigencia.
(**) Lo cual no es una opinión, como me dirían algunos, es algo ya evidenciado en el libro Accelerate y los DORA Reports de cada año.
(***) Criterio incorporado el 2021.