Este articulo puede ser considerado una continuación de los anteriores, pero en este caso vamos a tratar de ir al grano respecto a una situación que algunos todavía podemos estar pasando y sobre la cual no se ha tomado acción, asi que vamos a ello.
 Recordemos, desde diciembre del 2022 los runtime V2 y V3 de Azure Functions ya no están soportados, pero ¿eso significa que ya dejaron de funcionar las Functions que tenemos en producción? Pues no, ahí siguen operando a menos que Microsoft anuncie su apagado definitivo (como ya paso con otros servicios que comentamos aquí y aquí) peroooo…. sin garantías de que sigan funcionando como se espere, una razón (simplificando mucho) es que Microsoft puede “meter mano” en la infraestructura compartida pero teniendo en mira solo los parámetros de operación de la versión V4 (la soportada actualmente) y las versiones de los lenguajes soportados por V4. Por ejemplo si tu Function fue hecho en una versión de Node antigua (pero entonces soportada por la V3) y aun no has migrado a la V4, no hay garantías ni soporte del funcionamiento esperado de tu aplicación, si pues no hay “Pero si ayer funcionaba”, es que simplemente no se ha sido diligente en seguir los ciclos de vida de la tecnología que estamos usando.
Recordemos, desde diciembre del 2022 los runtime V2 y V3 de Azure Functions ya no están soportados, pero ¿eso significa que ya dejaron de funcionar las Functions que tenemos en producción? Pues no, ahí siguen operando a menos que Microsoft anuncie su apagado definitivo (como ya paso con otros servicios que comentamos aquí y aquí) peroooo…. sin garantías de que sigan funcionando como se espere, una razón (simplificando mucho) es que Microsoft puede “meter mano” en la infraestructura compartida pero teniendo en mira solo los parámetros de operación de la versión V4 (la soportada actualmente) y las versiones de los lenguajes soportados por V4. Por ejemplo si tu Function fue hecho en una versión de Node antigua (pero entonces soportada por la V3) y aun no has migrado a la V4, no hay garantías ni soporte del funcionamiento esperado de tu aplicación, si pues no hay “Pero si ayer funcionaba”, es que simplemente no se ha sido diligente en seguir los ciclos de vida de la tecnología que estamos usando.
Reiterando lo que ya conversamos anteriormente, esto deriva del principio de Responsabilidad Compartida, al elegir trabajar con un servicio IaaS, PaaS o un SaaS, estamos aceptando el nivel de intervención que el proveedor ha definido para ese tipo de servicio, así que un PaaS (como Azure Functions) va a implicar que el proveedor tome un rol muy proactivo respecto al ciclo de vida y mantenimiento del servicio que esta ofreciendo, así que si uno quiere que Azure lo “deje en paz” por mucho tiempo respecto al mantenimiento, pues… no queda sino optar por un servicio IaaS como las Máquinas Virtuales, con todo lo que eso implica.
Bueno, discusiones de obsolescencia aparte, queda claro que ya estamos tarde, si tenemos Functions de versión 3 o 4 nuestras aplicaciones ya no están bajo soporte, por lo que toca efectuar la migración respectiva (lo cual puede implicar cambios de código para alinearnos a versiones modernas de los lenguajes/frameworks), así que el primer paso sería averiguar que Functions requieren actualización.
Para este problema la solución mas “sencilla” seria revisar cada Functions y ver si hay alguna alerta, como la que vimos anteriormente: 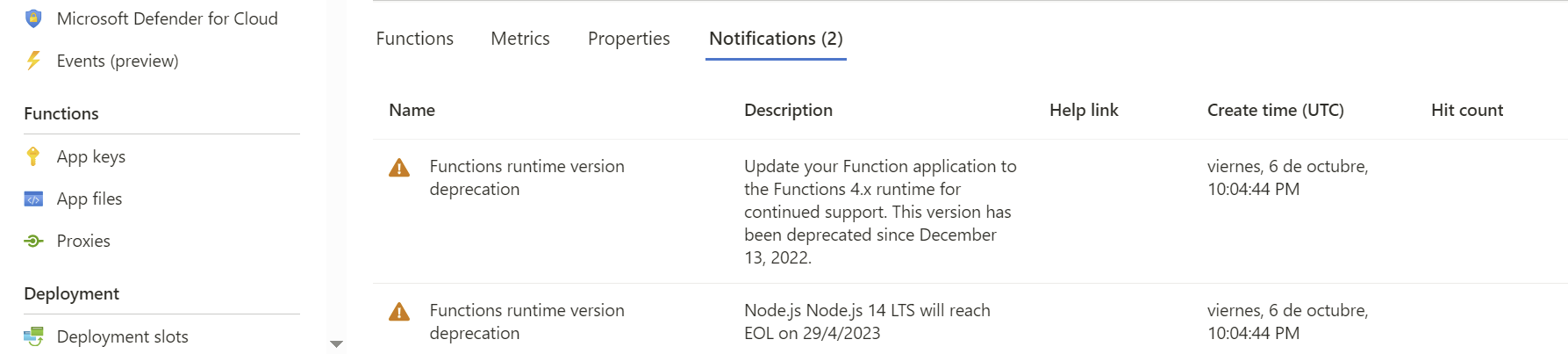
El problema es que esto solo tiene sentido si en nuestras subscripciones tenemos pocas Functions, por lo que el paseito seria sencillo, pero… si tenemos varias subscripciones y Functions desplegados ¿Como hacemos? Si, lo suyo seria algún query o script para lograrlo, así que usando Azure Copilot conseguí este query para ejecutar en Azure Graph:
resources
| where type == 'microsoft.web/sites'
| where properties.kind == 'functionapp'
| extend runtimeVersion = tostring(properties.siteConfig.netFrameworkVersion)
| where isnotnull(runtimeVersion) and runtimeVersion contains '4.'
| project id
La mala noticia es que este query no funciona, el valor “runtimeVersion” siempre retorna una cadena vacia, por lo que hacer comparaciones alrededor de este valor no tiene mucho sentido.
Asi que conversando con algunos MVPs me entere que el camino era el uso de PowerShell, y luego de unas pruebas vi que la solución que me brindo Brett Miller era la adecuada:
PS /home/brett> $query = "resources
| where type == 'microsoft.web/sites'
| where properties.kind == 'functionapp'
| extend runtimeVersion = tostring(properties.siteConfig.netFrameworkVersion) "
$functions = Search-azGraph -Query $query
PS /home/brett> $functions | foreach-object {
$appSettings = Get-AzFunctionAppSetting -Name $_.name -ResourceGroupName $_.resourceGroup
[pscustomobject]@{
functionname = $_.Name
runtimeVersion = $appSettings.FUNCTIONS_EXTENSION_VERSION
}
}
Claro que para que esto funcione debemos ejecutarlo en el lugar correcto: el Cloud Shell que nos da el Portal de Azure o el propio Cloud Shell de Windows, y para que el query se efectue correctamente hay que instalar el paquete respectivo, por lo que solo hay que ejecutar previamente esta linea dentro del Cloud Shell:
Install-Module -Name Az.ResourceGraph
Y como pueden ver, ahora si conseguí la información que estaba buscando:
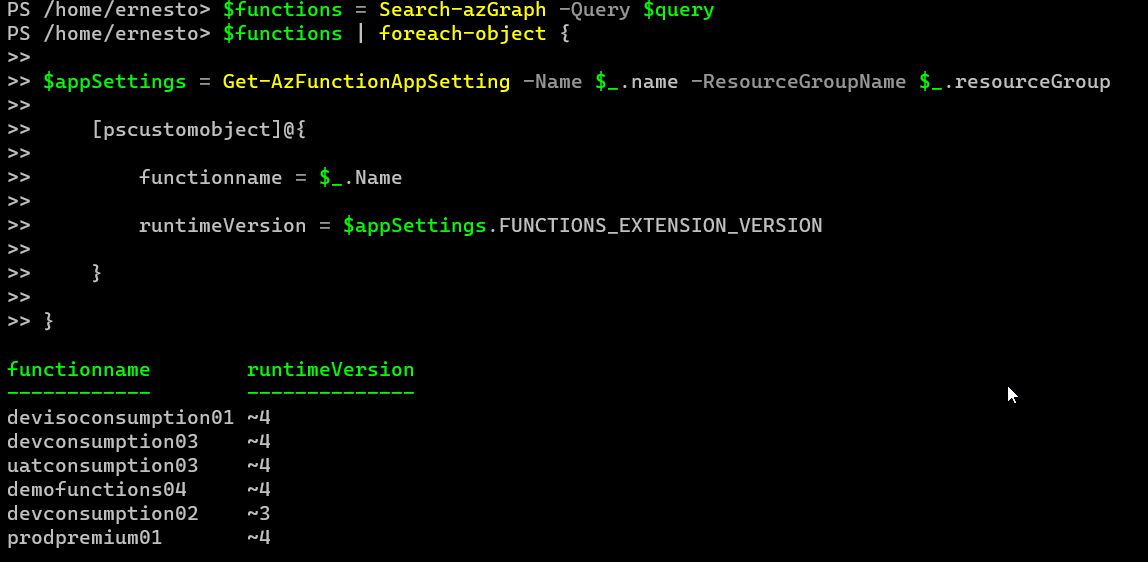
Upps… pensé que ya había migrado todos los Functions que uso para mis demos, a cualquiera le puede pasar, pero lo importante es que ya tenemos la información necesaria para ubicar nuestros Functions obsoletos y empezar la migración.
No puedo dejar de mencionar que Stefano Demiliani, otro fellow MVP, también encontró una solución para este problema, la cual esta detallada aquí.
Así que… ¡no hay excusas! ubica tus Functions a actualizar y ¡migra ya!