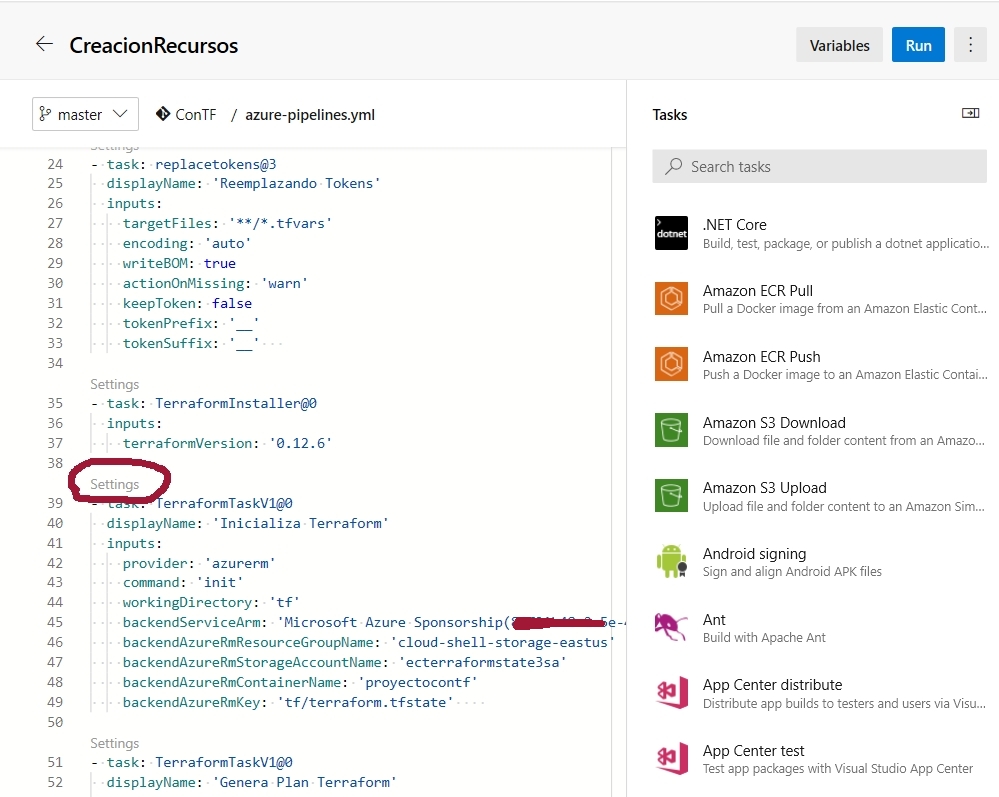
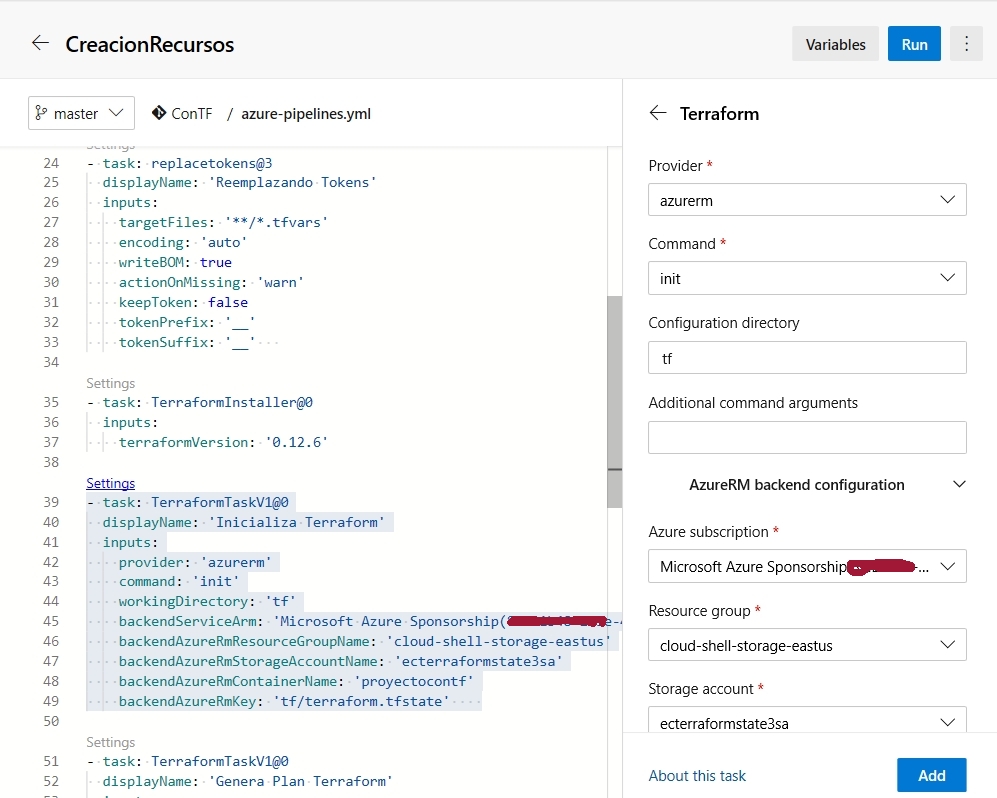
Seguridad, palabrita omnipresente en este mundo tecnológico pero que tantas confusiones trae a quienes de alguna manera tienen que lidiar con ella, ya sea estableciendo infraestructuras seguras, o desarrollando aplicaciones que no sean vulnerables a malos usos o ataques, y claro… con la nube hay cosas que toca revisitar, y … a eso vamos.
Este articulo no pretende ser una guía de como implementar la seguridad en Azure, pero si que espera contextualizar el entorno en que nos encontramos, como hemos llegado hasta el y una (entre otras) forma adecuada de gestionar la seguridad de nuestras aplicaciones en la nube.
En todo caso tenemos que partir de dos conceptos esenciales (otros son los relativos a la categorización de los recursos a proteger) en este rubro: Autenticación y Autorización.
Grosso modo, Autenticación es la capacidad de garantizar que quien quiere acceder a un recurso (sistema, dato, infraestructura) es quien dice ser, y esto se ha ido logrando mediante: contraseñas, biometría, tokens físicos, etc. Por otro lodo la Autorización se enfoca en la asignación correcta de los permisos respecto a que se puede hacer con el recurso en cuestión, dependiendo del rol o perfil de la persona ya Autenticada.
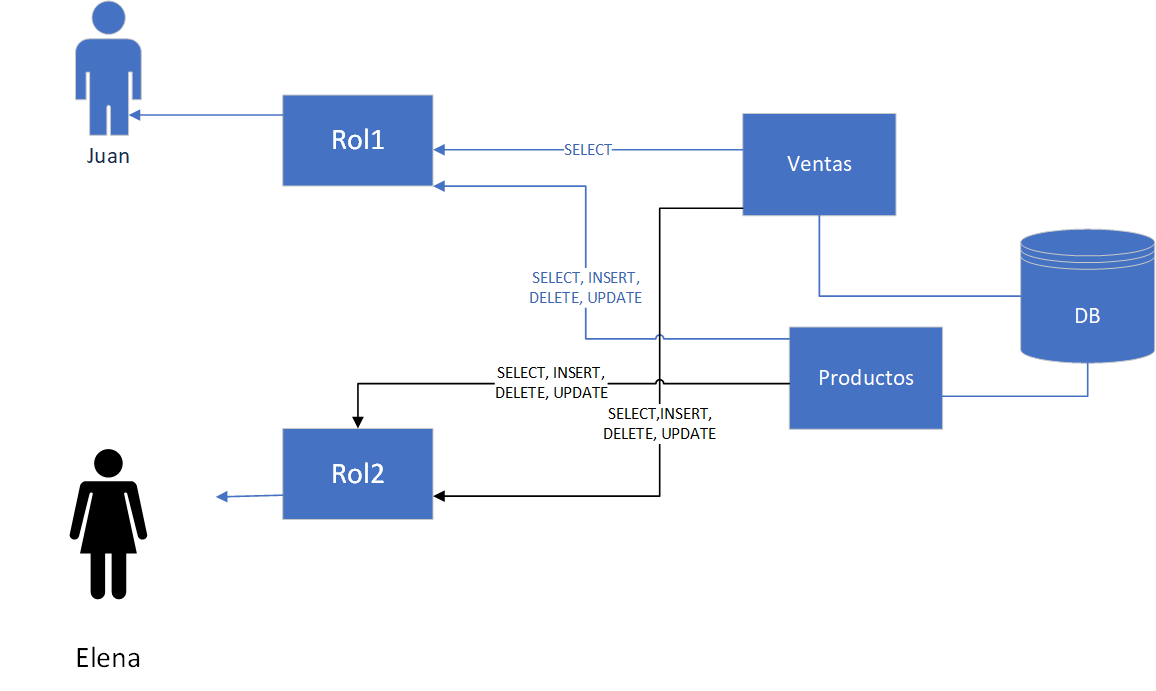
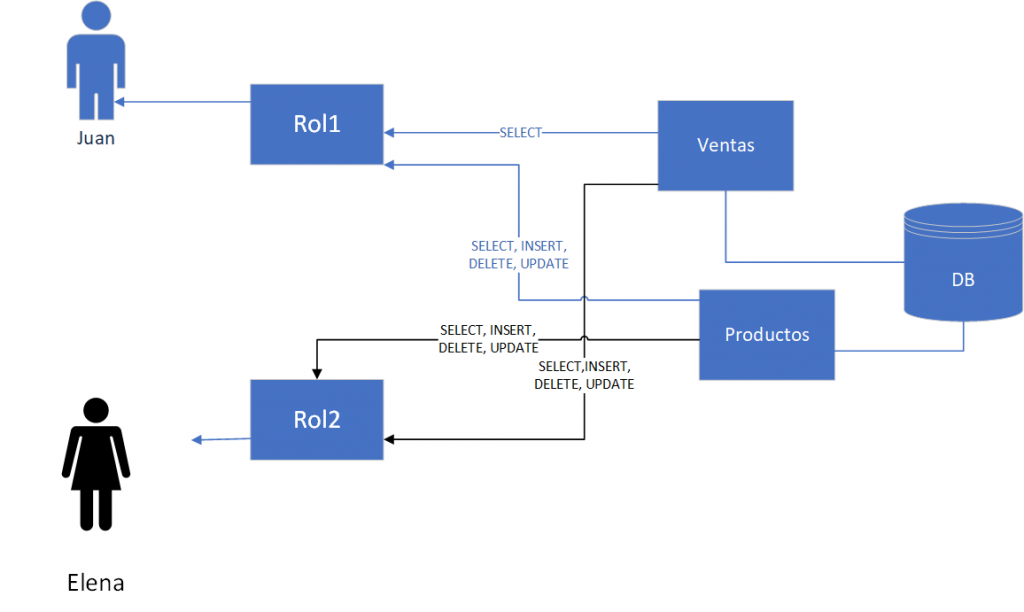
Hasta ahí todo claro, ahora reflexionemos como hemos trabajado con estos conceptos, supongamos que tenemos una BD llamada “Negocios” con dos tablas: “Productos” y “Ventas”, y supongamos que se necesita que Juan, pueda mantener el catálogo pero que solo pueda consultar las ventas realizadas, empecemos poco a poco.
Pues bien, para esto será necesario que Juan se autentique ante la BD, ya sea mediante usuario y password manejados por la BD, o que la BD “acepte” la autenticación que Juan ha hecho ante el Sistema Operativo, ya sea local o el de la organización, y por otro lado aplicar un GRANT al usuario “Juan” para que este solo puede hacer SELECT sobre la tabla “Ventas”, y además un GRANT para que este mismo usuario pueda hacer INSERT, SELECT, UPDATE y DELETE sobre “Productos”, pero no permisos para borrar la tabla o modificar su estructura, hasta aquí nada fuera de lo común, y con la misma lógica podríamos dar GRANT más generosos a Elena para que haga operaciones de mantenimiento sobre ambas tablas.
Esto de manera muy simplificada, en un entorno real y mas ordenado, lo usual es que se creen “roles” preestablecidos con las diversas combinaciones de permisos y de esta manera a Juan se le podría asignar un rol ya existente que tenga los permisos ya mencionados sobre “Ventas” y “Productos” (en este caso Rol1), siendo que luego a alguien nuevo se le asigne ese mismo Rol1, simplificando la administración en lugar de asignar los permisos de manera individual, como se ve aquí:
 Finish Reading: Conociendo los modelos de seguridad en la nube con Managed Identities (I)
Finish Reading: Conociendo los modelos de seguridad en la nube con Managed Identities (I)


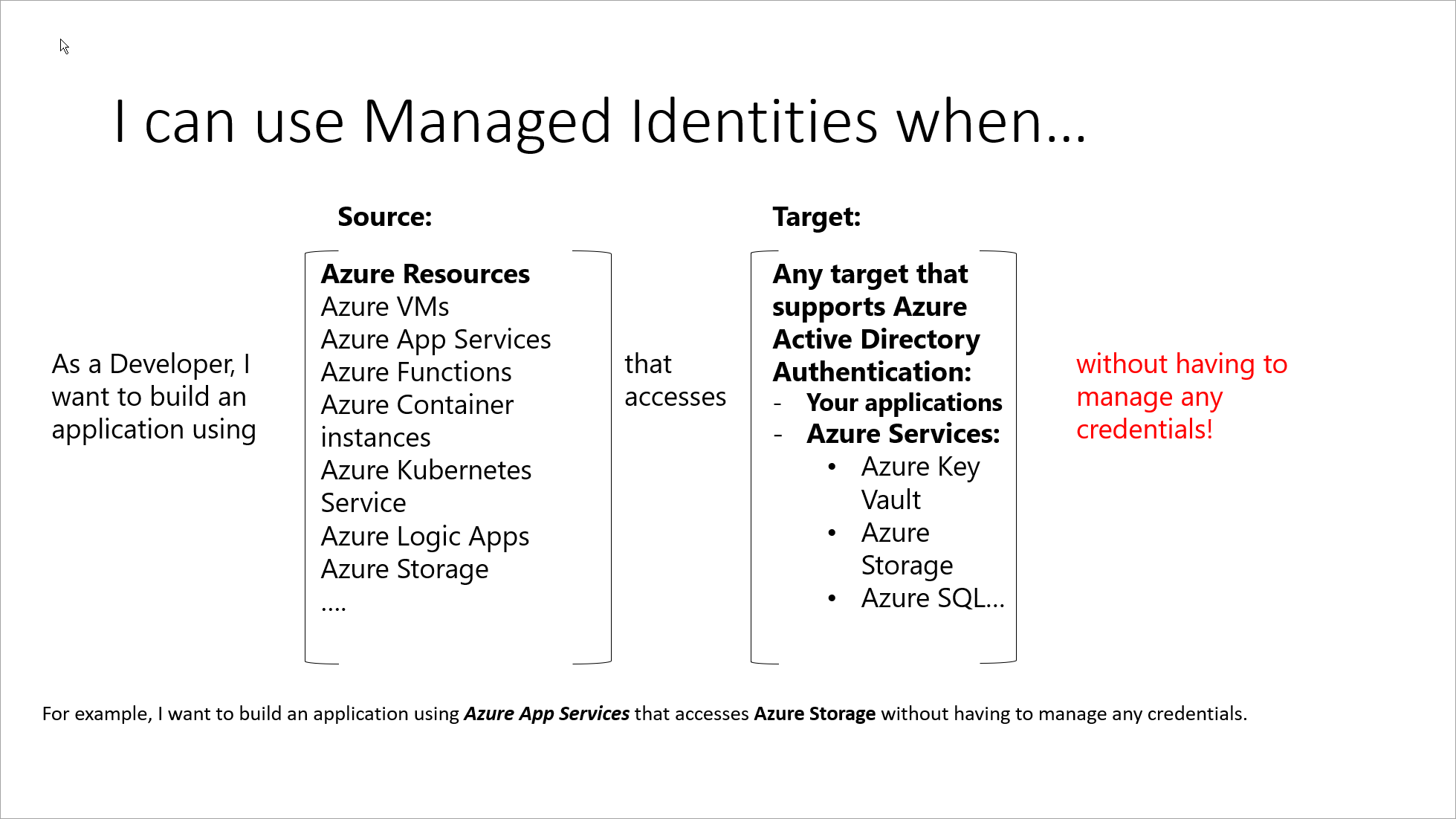 Finish Reading: Conociendo los modelos de seguridad en la nube con Managed Identities (y II)
Finish Reading: Conociendo los modelos de seguridad en la nube con Managed Identities (y II)