Una de las novedades por las que estaba mas expectante en este #MSIgnite de hoy era el anuncio de las Azure Container Apps, el nuevo servicio de Azure que hoy sale en Preview y que ya había tenido ocasión de probar en las ultimas semanas, pero … ¿por qué es tan importante este anuncio?
Para entenderlo hay que contextualizar como ha ido la evolución del mundo de los contenedores desde el boom iniciado por el querido Docker:
- Los contenedores se ejecutaban de uno en uno dentro de una unica computadora (generalmente una MV)
- Eventualmente se logra tener una pequeña orquestación de varios contenedores mediante Docker Composer
- Rápidamente surge la necesidad de orquestar y escalar «en serio» y a través de varias máquinas (un cluster), por lo que surgen diversos orquestadores tales como Mesos, Swarm, pero el que gano (para bien o para mal) fue Kubernetes.
Entonces ¿problema resuelto? pues no, ya que si bien Kubernetes nos brinda un contexto en el cual podemos desplegar nuestros contenedores y hacer que estos vayan escalando según la demanda, nos plantea una situación de la que debemos ser conscientes: la capacidad base (numero y tamaño de nodos del cluster) siempre esta encendida y hay que pagar por ella, lo cual nos puede derivar a escenarios de recursos de computo no aprovechados.
De esta forma… ¿qué hacer cuando nuestros requerimientos son pequeños y solo queremos lanzar UN contenedor? Pues bien para esa circunstancia se facilito el desplegar contenedores en Azure Web Apps, y surgieron los Azure Container Instances (ACI), de los cuales ya hablamos en nuestra serie sobre serverless, tecnología muy interesante que permitió el surgimiento de KEDA, servicio el cual facilita a un cluster de Kubernetes escalar de manera elástica sin agregar nuevos nodos (mediante un esquema orientado a eventos similar a Azure Functions), solo contenedores «autónomos», ayudando a un objetivo que se vuelve recurrente; «escalar a 0», que no es otra cosa que si deja de haber demanda sobre un pod/contenedor su numero de instancias en ejecución pase a ser 0. Nada mal esto de KEDA ¿No?
 Pues si, KEDA es de gran ayuda, pero pero pero… aun necesitas tener un Kubernetes, y toda su complejidad añadida, para lograr el efecto, así que ahí entran las Azure Container Apps, que es la propuesta de Microsoft para lograr la simplicidad en el despliegue escalable de contenedores para que de esta manera nos enfoquemos en el desarrollo de nuestras aplicaciones, y no en la infraestructura, infraestructura que por detrás esta soportada por el Control Plane de AKS, pero eso es transparente para nosotros.
Pues si, KEDA es de gran ayuda, pero pero pero… aun necesitas tener un Kubernetes, y toda su complejidad añadida, para lograr el efecto, así que ahí entran las Azure Container Apps, que es la propuesta de Microsoft para lograr la simplicidad en el despliegue escalable de contenedores para que de esta manera nos enfoquemos en el desarrollo de nuestras aplicaciones, y no en la infraestructura, infraestructura que por detrás esta soportada por el Control Plane de AKS, pero eso es transparente para nosotros.
Y..¿Qué tipo de contenedores podemos desplegar? pues esencialmente: Microservicios, APIs HTTP, Proceso de Eventos, y procesos backend de larga duración.
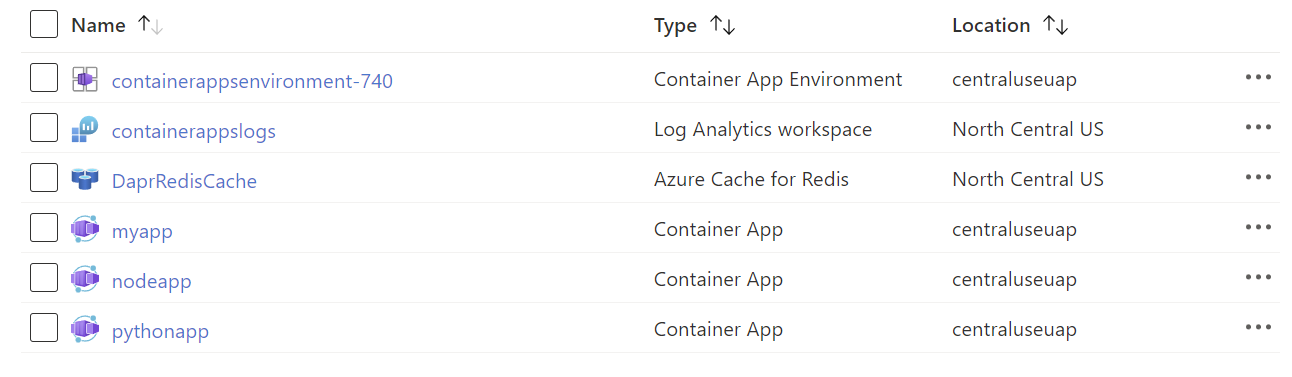
Esta es la definición pero… ¿como esto se lleva a la practica? Para entenderlo trataremos de conocer los elementos fundamentales de esta tecnología, así que les muestro un Grupo de Recursos, donde ya tengo desplegado unas ACA: